
A few weeks ago, us at Evolving Web finished migrating the Princeton University Press website to Drupal 8. The project was over 70% migrations. In this article, we will see how Blackfire helped us optimize our migrations by changing around two lines of code.
Before we start
- This article is mainly for PHP / Drupal 8 back-end developers.
- It is assumed that you know about the Drupal 8 Migrate API.
- Code performance is analyzed with a tool named Blackfire.
- Front-end performance analysis is not in the scope of this article.
The Problem
Here are some of the project requirements related to the problem. This would help you get a better picture of what's going on:
- A PowerShell script exports a bunch of data into CSV files on the client's server.
- A custom migration plugin
PUPCSVuses the CSV files via SFTP. - Using hook_cron() in Drupal 8, we check hashes for each CSV.
- If a file's MD5 hash changes, the migration is queued for import using the Drupal 8 Queue API.
- The CSV files usually have 2 types of changes:
- Certain records are updated here and there.
- Certain records are added to the end of the file.
- When a migration is executed, migrate API goes line-by-line, doing the following things for every record:
- Read a record from the data source.
- Merge data related to the record from other CSV files (kind of an inner join between CSVs).
- Compute hash of the record and compare it with the hash stored in the database.
- If a hash is not found in the database, the record is created.
- If a hash is found and it has changed, the record is updated.
- If a hash is unchanged, no action is taken.
While running migrations, we figured out that it was taking too much time for migrations to go through the CSV files, simply checking for changes in row hashes. So, for big migrations with over 40,000 records, migrate was taking several minutes to reach the end of file even on a high-end server. Since we were running migrate during cron (with Queue Workers), we had to ensure that any individual migration could be processed below the 3 minute PHP maximum execution time limit available on the server.
Analyzing migrations with Blackfire
At Evolving Web, we usually analyze performance with Blackfire before any major site is launch. Usually, we run Blackfire with the Blackfire Companion which is currently available for Google Chrome and Firefox. However, since migrations are executed using drush, which is a command line tool, we had to use the Blackfire CLI Tool, like this:
$ blackfire run /opt/vendor/bin/drush.launcher migrate-import pup_subjects
Processed 0 items (0 created, 0 updated, 0 failed, 0 ignored) - done with 'pup_subjects'
Blackfire Run completedUpon analyzing the Blackfire reports, we found some 50 unexpected SQL queries being triggered from somewhere within a PUPCSV::fetchNextRow() method. Quite surprising! PUPCSV refers to a migrate source plugin we wrote for fetching CSV files over FTP / SFTP. This plugin also tracks a hash of the CSV files and thereby allows us to skip a migration completely if the source files have not changed. If the source hash changes, the migration updates all rows and when the last row has been migrated, we store the file's hash in the database from PUPCSV::fetchNextRow(). As a matter of fact, we are preparing another article about creating custom migrate source plugin, so stay tuned.
We found one database query per row even though no record was being created or updated. Didn't seem to be very harmful until we saw the Blackfire report.
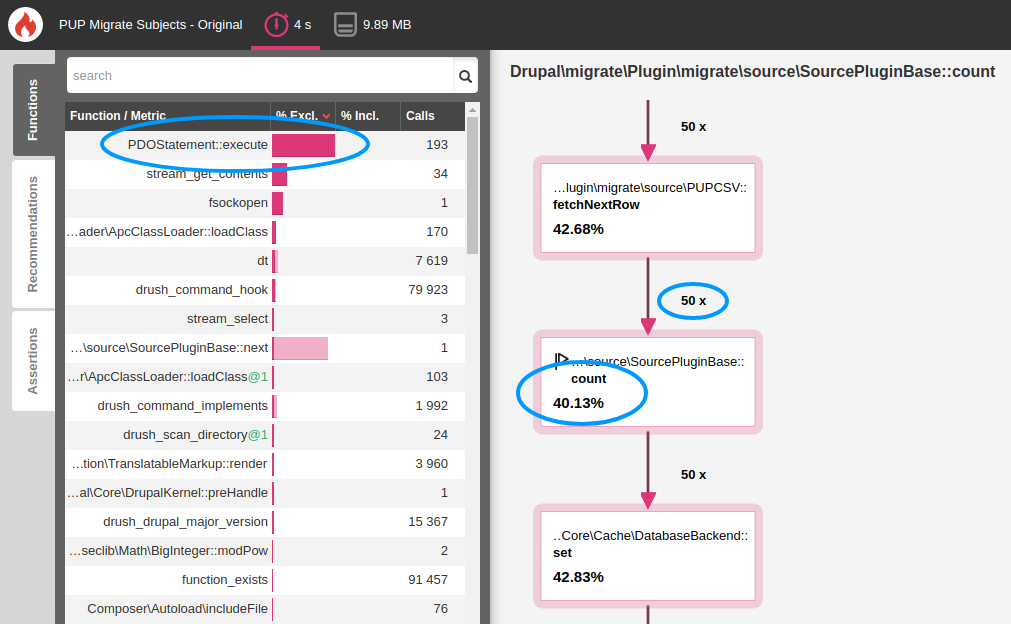
Code before Blackfire
Taking a closer look at the RemoteCSV::fetchNextRow() method, a call to MigrateSourceBase::count() was found. It was found that the count() method was taking 40% of processing time! This is because it was being called for every row in the CSV. Since the source/cache_counts parameter was not set to TRUE in the migration YAML files, the count() method was iterating over all items to get a fresh count for each call! Thus, for a migration with 40,000 records, we were going through 40,000 x 40,000 records and the PHP maximum execution time was being reached even before migrate could get to the last row! Here's a look at the code.
protected function fetchNextRow() {
// If the migration is being imported...
if (MigrationInterface::STATUS_IMPORTING === $this->migration->getStatus()) {
// If we are at the last row in the CSV...
if ($this->getIterator()->key() === $this->count()) {
// Store source hash to remember the file as "imported".
$this->saveCachedFileHash();
}
}
return parent::fetchNextRow();
}Code after Blackfire
We could have added the cache_counts parameter in our migration YAML files, but any change in the source configuration of the migrations would have made migrate API update all records in all migrations. This is because a row's hash is computed as something like hash($row + $source). We did not want migrate to update all records because we had certain migrations which sometimes took around 7 hours to complete. Hence, we decided to statically cache the total record count to get things back in track:
protected function fetchNextRow() {
// If the migration is being imported...
if (MigrationInterface::STATUS_IMPORTING === $this->migration->getStatus()) {
// Get total source record count and cache it statically.
static $count;
if (is_null($count)) {
$count = $this->doCount();
}
// If we are at the last row in the CSV...
if ($this->getIterator()->key() === $count) {
// Store source hash to remember the file as "imported".
$this->saveCachedFileHash();
}
}
return parent::fetchNextRow();
}Problem Solved. Merci Blackfire!
After the changes, we ran Blackfire again and found things to be 52% faster for a small migration with 50 records.
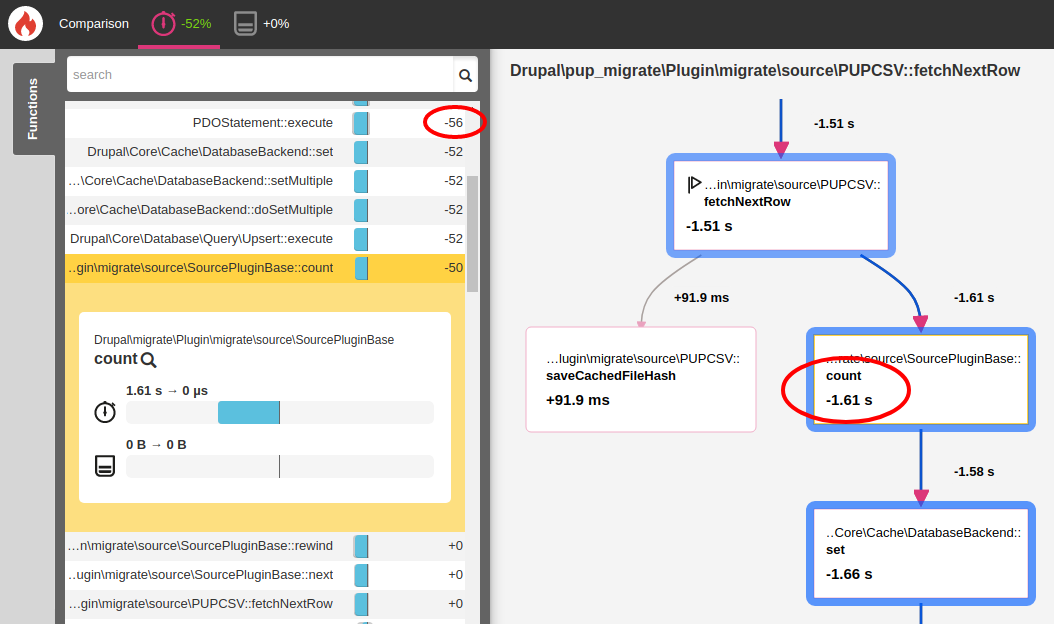
For a bigger migration with 4,359 records the migration import time reduced from 1m 47s to only 12s which means a 98% improvement. Asking why we didn't include the screenshot for the bigger migration? We did not (or rather could not) generate a report for the big migration because of two reasons:
- While working, Blackfire stores function call and other information to memory. Running a huge migration with Blackfire might be a bit slow. Besides, our objective was to find the problem and we could do that more easily while looking at smaller figures.
- When running a migration with thousands of rows, the migration functions are called over thousands of times! Blackfire collects data for each of these function calls, hence, the collected data sometimes becomes too heavy and Blackfire rejects the huge data payload with an error message like this:
The Blackfire API answered with a 413 HTTP error ()
Error detected during upload: The Blackfire API rejected your payload because it's too big.Which makes a lot of sense. As a matter of fact, for the other case study given below, we used the --limit=1 parameter to profile code performance for a single row.
A quick brag about another 50% Improvement?
Apart from this jackpot, we also found room for another 50% improvement (from 7h to 3h 32m) for one of our migrations which was using the Touki FTP library. This migration was doing the following:
- Going through around 11,000 records in a CSV file.
- Downloading the files over FTP when required.
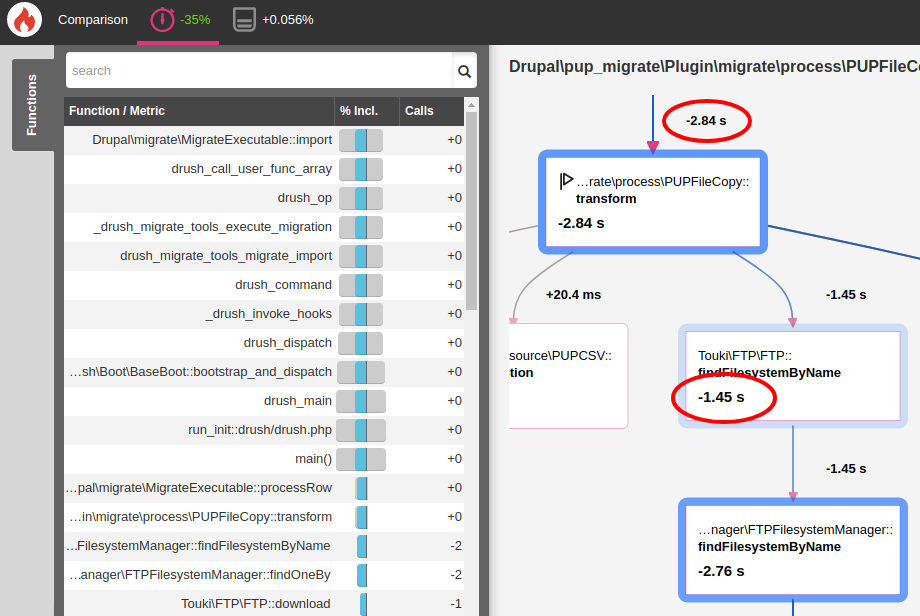
A Blackfire analysis of this migration revealed something strange. For every row, the following was happening behind the scenes:
- If a file download was required, we were doing
FTP::findFileByName($name). - To get the file, Touki was:
- Getting a list of all files in the directory;
- Creating
Fileobjects for every file; - For every file object, various permission, owner and other objects were created.
- Passing all the files through a callback to see if it's name was
$name. - If the name was matching, the file was returned and all other
Fileobjects were discarded.
Hence, for downloading every file, Touki FTP was creating 11,000 File objects of which it was only using one! To resolve this, we decided to use a lower-level FTP::get($source, $destination) method which helped us bypass all those 50,000 or more objects which were being created per record (approximately, 11,000 * 50,000 or more for all records). This almost halved the import time for that migration when working with all 11,000 records! Here's a screenshot of Blackfire's report for a single row.
So the next time you think something fishy is going on with code you wrote, don't forget to use use Blackfire! And don't forget to leave your feedback, questions and even article suggestions in the comments section below.
More about Blackfire
Blackfire is a code profiling tool for PHP which gives you nice-looking reports about your code's performance. With the help of these reports, you can analyze the memory, time and other resources consumed by various functions and optimize your code where necessary. If you are new to Blackfire, you can try these links:
- Read a quick introduction to Blackfire.
- Read documentation on installing Blackfire.
- Read the 24 Days of Blackfire tutorial.
Apart from all this, the paid version of Blackfire lets you set up automated tests and gives you various recommendations for not only Drupal but various other PHP frameworks.
Next Steps
- Try Blackfire for free on a sample project of your choice to see what you can find.
- Watch video tutorials on Blackfire's YouTube channel.
- Read the tutorial on creating custom migration source plugins written by my colleague (coming soon).